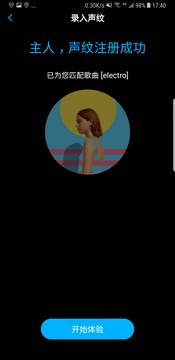
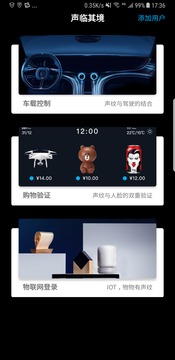
声临其境是一款基于声纹识别技术进行身份认证的体验工具,应用于物联网各个场景之中,如车载系统启动、多媒体控制,声纹购物身份验证,家庭智能识别个性化设置。
体验者需录入自己的声音,即可生成属于自己的声纹特征,即可进入各个场景中体验。
- 高精确率:业界内环比,我们的核心算法,让其拥有惊人的超高精确率。
- 安全可靠:基于高精准识别,你专属声纹所建立的身份将独一无二,安全可靠。
- 快速高效:目前2秒即可识别出你的身份,并且识别速度仍在不断提高。
- 多类型: Speakin目前支持3种模型,普通话文字模型,数字模型,混合模型。
- 多平台: 利用生物ID的唯一性,让你更便于统一管理各平台虚拟ID。
关注公众号可获取更多你想要的信息:SpeakIn
更新内容
声临其境3.1.0版
1.新增公安与电话远程声纹对比场景
2.除场景体验外,提供功能模块试用
1:1/1:N声纹对比
人声分割/过滤
性别检测
情绪检测
 Shizuku应用管理app
Shizuku应用管理app
11.17MB
系统安全4
 超级网盘最新版
超级网盘最新版
58.96MB
系统安全4
 北京液化气北京液化气管理服务平台
北京液化气北京液化气管理服务平台
40.09MB
系统安全4
 qlv格式转换器免费版
qlv格式转换器免费版
12.09MB
系统安全4
 超级计算机下载v2.00
超级计算机下载v2.00
12.76M
系统安全4
 OKAI电瓶车
OKAI电瓶车
32.86MB
系统安全4

miui手机管家最新版5.5.8

wifi管理器手机版app

wifi分析助手电脑版

手机快传助手

创新万能遥控器

番茄手机管家

彩映证件照

优聚搜

AI剪辑师

出租车打表器

EV投屏

数铠云盘
对于您的问题我们深感抱歉,非常感谢您的举报反馈,小编一定会及时处理该问题,同时希望您尽可能的填写全面,方便小编检查具体的问题所在,及时处理,再次感谢!